cours de : Méthodologie de la recherche
Jean-Éric PELET
Agenda
- Introduction : différencier les études qualitatives des études quantitatives
- L'étude de marché
- L'étude documentaire
- L'étude qualitative
- L'étude quantitative
- Les techniques qualitatives de collecte de données
- Les techniques qualitatives individuelles
- Entretiens non-directifs
- Entretiens semi-directifs
- L’analyse de contenu
- Les techniques d’observation
- L’observation simple
- L’observation verbalisée
- L’observation appareillée
- Les techniques de groupe
- Le groupe de discussion
- Le focus group
- La technique du groupe nominal
- La méthode Delphi
- Les techniques associatives
- Les techniques projectives
- Les techniques de créativité
- La collecte des données par questionnaire
- Les différentes techniques de constitution d’un échantillon de répondants
- La détermination de la taille de l’échantillon à constituer
- La construction d’un questionnaire
- Les règles de fond
- Le contenu des questions
- Les types de questions (ouvertes, fermées, échelles d’attitude)
- Les propriétés des échelles de mesure.
- Les règles de forme
- La rédaction du questionnaire
- La structure du questionnaire
- La présentation du questionnaire
- La codification du questionnaire
- Introduction à l’analyse de données
- L’analyse univariée
- Les tableaux de fréquences
- Les statistiques descriptives
- L’analyse bivariée
- Classification des techniques d’analyse bivariée
- L’analyse des tableaux de contingence
- Les comparaisons de moyenne
- La corrélation
- La régression simple
- L’analyse multivariée
- Classification des techniques d’analyse multivariée
- L’analyse factorielle
- La régression multiple
- L’analyse conjointe
- L’analyse typonomique
Introduction : l'arbitrage entre études qualitatives et études quantitatives
But du cours : savoir trouver et utiliser les outils de recherche.
- Méthode de collecte dinformation : interroger les gens en groupe. Sil n'existe pas de dimensions sociales sous-jacentes au sujet, aucun intérêt à faire des entretiens de groupe.
Le groupe de discussion
Le focus group
top | 1.3.3. Technique du groupe nominale « TGN »
- Entretien directif, on pose directement les questions
- Gratuit, efficace
- Possibilité dêtre influencé par un « leader »
- Doù lidée de recourir à des phases de questionnements individuels et des phases de questionnements collectifs.
Méthode qui se déroule sur cinq/six étapes (1/2 journée)
Un grand tableau/paper board lancer le sujet
Phase 1 : Questionnaire individuel distribué
- les gens rassemblent leurs idées pour répondre aux questions.
Phase 2 : Rôle important de lanimateur qui choisit un participant au hasard qui décline ses réponses, inscrites au tableau (idem pour chaque participant).
- D'où une liste d'idées importantes à la fin.
Phase 3 : Epuration de cette liste.
- Deux personnes peuvent dire la même chose par exemple,
- Création dune échelle par la suite,
- Lanimateur engage le groupe à discuter de cette liste.
Phase 4 : Evaluation des idées individuelles
- Lanimateur repose la même question quà létape 1
- Les répondants confirment leurs idées,
- ou donnent des idées influencées plus par le groupe.
Phase 5 : Recueil des réponses de la phase 4
Graphique camembert statistiques
- Analyse de contenu manuelle : chaque terme recensé : calcul du % dapparition didée,
- On donne au groupe létat des lieux avec lanalyse du contenu chiffrée (tel mot, x%, tel mot y%),
- Relancer le dialogue.
Phase 6 : Evaluation définitive qui reprend la forme dun questionnement individuel :
- On donne une grille avec toutes les idées du groupe,
- Chaque idée correspond à une échelle sémantique :
- idée très importante
- idée peu importante
- idée pas importante
- Les échelles ont une propriété métrique permettant des calculs de moyenne afin de hiérarchiser par ordre croissant ou décroissant les idées de la recherche.
- Cette méthode permet de laisser de côté certaines pistes pour ne pas alourdir inutilement le terrain.
- But : minimiser les phénomènes dinfluence interpersonnels.
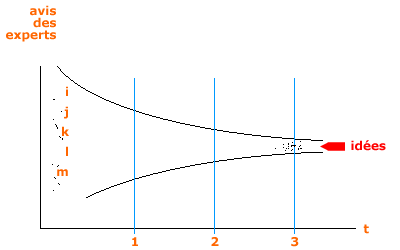
1.3.4. Méthode DELPHI : (entretien directif)
- Méthode prévisionnelle (non exploratoire, proche de qualitatif, confirmatoire) qui permet de déboucher sur des résultats sur lesquels on peut prendre des décisions.
- Cest une réunion dexperts du domaine traité, le but étant de prévoir les parts de marché d1 pendant quil nest pas encore lancé par exemple.
- Ex. : tester lacceptabilité dune nouvelle technologie
- Très petit groupe (8 10)
- Idée : Interroger à trois reprises les individus sur le même sujet.
- Généralement, lenquête est menée par voie postale car les experts sont peu disposés.
- Enquête à distance donc.
- Méthode :
- Envoi des questions avec délai à respecter.
- La liste des experts nest pas communiquée à chaque expert : anonymat.
- Dès les premiers retours : analyse de contenu.
- Ce qui revient le plus souvent est quantifié pour pouvoir faire un état des lieux.
- Renvoyer ensuite les mêmes questions avec les résultats en influençant positivement chaque expert, le but étant que le groupe converge (on tente daboutir à un consensus).
- Attente des retours puis 3ème envoi (de lanalyse de contenu).
1.4 Techniques associatives
- Etablir des associations entre différents éléments grâce à des supports très variés (photos, dessins, phrases, objets, etc.).
- Méthodes très qualitatives permettant de contourner des résistances individuelles.
- Ex. : si votre société était une couleur, ce serait ...
- On cherche à trouver des associations par relation grâce à des supports particuliers : photos, dessins, mots objets, etc.
1.4.1. Techniques projectives
- Empruntées à la théorie de Freud
- Définition de projection :
Attribution à autrui des sentiments jugés répréhensibles.
- On attribue plus facilement aux autres les désirs et motivation quon naccepte pas, on ne reconnaît pas comme sien,
- Expulsion sur autrui des sentiments que lon juge répréhensibles chez soi.
- Présenter lautre comme lagresseur.
Intérêt : Repérer ce que lindividu ? projette sur lindividu ß.
- Nous saurons mieux qui est ? de cette façon.
- Lindividu va parler de lui sans avoir parlé de lui, sans se sentir impliqué.
Théorie de la forme :
Théorie allemande, la « Gestatt theorie »
- Linformation mémorisée, linformation perçue nest pas réductible à la somme des éléments perçus.
- Lindividu cherche à organiser ses perceptions sous forme structurée. Les formes sont gouvernées par un principe déquilibre.
- Ex. : Face à un tableau de Picasso, on peu être « perdu » perceptuellement. Chacun organise alors ce quil voit à sa façon. Chacun aime pouvoir dire ce quil voit (processus intellectuel conscient).

Pablo Picasso (source)
- Pourquoi en voyant un même tableau, allons-nous penser des choses différentes ?
- Parce que cest une projection, toujours à linstant « t ». La projection permet dinterpréter quelque chose qui, à la base, ne létait pas. Cest un besoin. Assez proche de la catégorisation.
Points communs des tests projectifs :
- Ils se caractérisent par lambiguïté du support matériel;
- Le support est source dinterprétation différente;
- Ambiguïté des relations entre les gens;
- Test parfois utilisé pour un entretien dembauche alors que ce nest pas fait pour cela (antinomie car cest très intime);
- Le matériel utilisé est standard et ne varie pas entre les individus.
- Le recours aux tests projectifs quand on fait lhypothèse que les mécanismes de défense individuels sont tels quon pense quils seront plus facilement débloqués par ces méthodes
- Il nexiste pas de bonnes ou de mauvaises réponses avec les techniques projectives.
A. T.A.T. de Murray (international)
(Thematic Aperception Test - test de perception thématique)
- Environ 20 photos sans rapport les unes aux autres,
- Laisser du temps à lobservateur.
- Celui-ci raconte une histoire par la suite (Que vous suggère cette image ? Racontez-moi lhistoire de ce dessin).
Analyse : A chaque histoire, il existe un héros.
Idée : Le répondant a tendance à projeter ce quil est avec ce héros.
- Mais ce héros nest peut-être pas présent sur la photo. Elle suscite, évoque des choses.
- Analyse des motivations de lindividu à travers le caractère décelé par le héros de héros de lhistoire.
Les focus de pression (environnement, familial, professionnel, privé) sont aussi analysés pour comprendre ce que fait le héros.
- Richesse de lhistoire et vocabulaire analysés sont aussi importants.
- Les planches ne sont pas toutes destinées aux mêmes personnes (enfants, etc.).
B. La liste dachats
La liste dachats est rédigée.
Une autre liste est rédigée en modifiant une seule variable : lobjet de la recherche
:

Résultats : décrire la ménagère qui a acheté les produits et indiquer les raisons qui nous poussent à écrire (personnes dépensières, paresseuses, etc.), tels sont les résultats présentés.
- Possibilité de faire de même avec une technologie.
C. Les phrases à compléter
- Rédiger des phrases liées à notre sujet, avec des blancs.
- Ex. : Les utilisateurs dInternet sont plutôt : __________
- Le répondant parle au nom dautrui. Il parle des autres (déculpabilisation).
- Pour linterprétation : analyse de contenu, moyenne de répétition didées, de mots, etc.
D. Test dassociation de mots
Créé par Carl Jung
- Quatre listes de 100 mots (de la vie de tous les jours).
- En lisant les mots un à un, quest-ce quil vient spontanément à lesprit quand on dit tel mot ?
- Principe du questionnaire chinois : "Si mon entreprise était un personnage historique, ce serait
" (principe du questionnaire chinois)
1.4.2. Les techniques de créativité
- Face à un groupe, on soumet un problème/sujet.
- Sortie de lentretien : on ressort avec une liste de mots.
- Ex. : le brainstorming (non valorisant dans une thèse).
- But : dynamiser le groupe, participer, donner des idées.
- (ex. : Cest quoi un site Internet idéal ?).
- Dans le brainstorming, tout le monde participe.
Il faut maintenant créer un lien entre le qualitatif et le quantitatif : on passe de lexploratoire à lexploration.
- Caractéristiques des études qualitatives : les échantillons sont assez petits.
- Quand on passe à du quantitatif, léchantillon devient plus important.
- Interrogation sur la taille,
- Interrogation sur la manière de constituer léchantillon : qui interroger ?
top | 2. La collecte des données/questionnaire
Méthodes aléatoires (probabilités) : les plus riches
- Méthode de constitution de léchantillon fondée sur le hasard.
- Le chercheur ninterviendra pas pour décider qui fera partie (on non) de léchantillon.
- Cest le hasard qui décide à sa place.
Méthodes empiriques (non probabilistes)
- Méthodes dans lesquelles le chercheur met au point une procédure subjective de sélection des individus.
Linférence statistique
- Ne peut sopérer quavec les méthodes aléatoires
Echantillon aléatoire simple
- Disposer dune lise complète dindividus de la population totale,
- Plus il y a dhomogénéité à lintérieur dune strate en terme de réponse, plus on av la sous représenter.
- En revanche, plus il y a dhétérogénéité à lintérieur dune strate en terme de réponses, plus il faut la sur représenter.
Echantillon stratifié
- Constitution des strates : quelles sont les bonnes variables de stratification à utiliser par rapport à mon sujet détude ?
Méthode : Reproduire au niveau de léchantillon les proportions observées au niveau de la population.
Les tests statistiques
- Ils permettent dappréhender la significativité des résultats au sein de notre échantillon.
Ne pas confondre significativité et représentativité.
But : Comparer des pourcentages et savoir si on peut ou non interpréter les pourcentages dun échantillon à une population totale.
- Si le test est négatif, cest-à-dire que le différentes catégories de léchantillon donnent des résultats différents, le test nest pas significatif, ce qui fait que lon ne peut affirmer la significativité.
- On ne peut interpréter à lil nu des chiffres.
Approche hypothético-déductive
Partie 1
- Revue de littérature
- Variables :
- Explicatives (indépendantes)
- A expliquer (dépendantes)
- Etude qualitative
- Faire parler les gens pou voir des différentes formes quune variable peut prendre
- Ce qui permet à la fin de cette partie, de hiérarchiser les variables pour ensuite faire un « zoom » derrière les variables qui nous ont intéressés.
- Létude qualitative permet de savoir ce quon utilise derrière nos variables.
- Modalité dune variable
- Ex. : variable CSP a 8 modalités
- la qualité d'une recherche est basée sur la pertinence du modèle
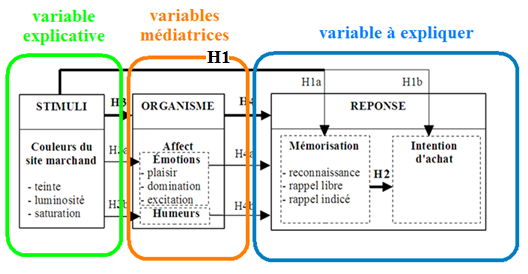
- H1 : les composantes (teinte, luminosité, saturation) des couleurs d’un site web marchand entraînent un effet positif sur la mémorisation et sur l'intention d'achat.
- Toutes les hypothèses sont censées apporter des éléments de réponse à la problématique.
- Ex. : Quelles dimensions constitutives dun site sont supposées influer sur le comportement de linternaute
- H2 : Les composantes (teinte, luminosité, saturation) des couleurs d’un site web marchand influencent positivement les états affectifs des internautes.
Partie 2
- Le déroulement de la partie 2 se fait en fonction des résultats que lon obtient des hypothèses.
- Exemple de tri par traitement statistique à faire pour expliquer H1 (3 variables explicatives - les 3 composantes de la couleur et 2 variables à expliquer - la mémorisation et l'intention d'achat).
1 |
Teinte |
Mémorisation |
| Teinte |
Intention d'acheter |
2 |
Luminosité |
Mémorisation |
| Luminosité |
Intention d'acheter |
3 |
Saturation |
Mémorisation |
| Saturation |
Intention d'acheter |
- Six croisements différents = Six séries de tests
- Si les six croisements naboutissent à rien, on dit que les hypothèses sont infirmées.
- H1 ne sera validée à 100 % que si les six croisements sont bons.
- « Lhypothèse H1 selon laquelle la couleur est responsable du comportement de linternaute est partiellement vérifiée » (si seulement trois sur six croisements sont validés).
- Vérifier H1 cest confirmer que la couleur influe positivement sur le comportement du consommateur.
- Infirmer H1 cest confirmer que la couleur influence négativement sur le comportement du consommateur.
- Si le résultat est : « la couleur ninfluence pas le comportement du consommateur » alors léchantillon nest pas significatif.
top | Le questionnaire
- Il découle du modèle de recherche.
- Sa rédaction permet de vérifier ce quon trouve dans le modèle.
- Chaque « ___ » dans chaque bloc est une question qui contient plusieurs modalités.
- Ex. : couleur chaude/froide.
- On ne pose que des questions issues du modèle.
- Le questionnaire sert à confirmer.
- Pas de questions ouvertes SAUF si on réussit à les pré-coder.
2.1 Les différentes techniques de constitution dun échantillon de répondants
- Problème de la représentativité des résultats
- La population totale* par cible, de référence, mère
- Base du sondage**
* Population totale :
- ensemble des objets (individus, consommateurs, ensemble, etc.) qui possèdent les informations recherchées pour répondre aux objectifs de notre recherche.
** Base de sondage :
- Représentation concrète des éléments de la population cible.
- Liste à partir de laquelle on sélectionne les individus de léchantillon (ex. : utilisation de lannuaire).
Objectif : Avoir une base de sondage adaptée à la population totale.
- Le décalage sappelle lerreur de couverture, quand la base ne couvre pas la population.
- Pas de règle absolue, cest du bon sens
- Certains individus de la population cible ont une probabilité nulle de faire partie de l'échantillon qu'on constitue.
Méthode : Sélectionner les répondants en utilisant les techniques déchantillonnage.
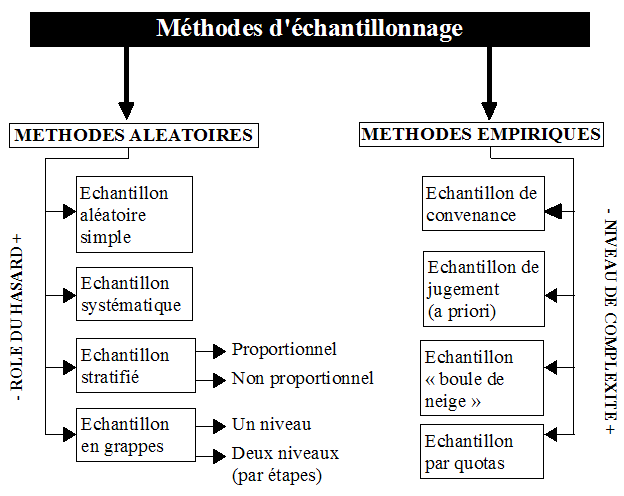
- Il existe deux grandes familles :
- Méthodes aléatoires, probabilistes
- Méthodes empirique, non probabiliste
- Inférence statistique : Passage de léchantillon (non systématique, dépend des tests statistiques) à la population totale.
Echantillon aléatoire :
- Echantillon dans lequel tout individu de la population cible peut figurer, ceci avec une probabilité connue à lavance par nous et proche de zéro.
Echantillon non aléatoire :
- La constitution de léchantillon repose sur une procédure élaborée par le chercheur et lorsque la probabilité de sélection de chaque unité nest pas connue à lavance.
- Ex. : enquête dans la rue, dans une galerie marchande, etc.
- Les échantillons aléatoires permettent des calculs de probabilité tandis que les échantillons non aléatoires ne le permettent pas.
- Un échantillon est aléatoire quant cest le hasard qui choisit.
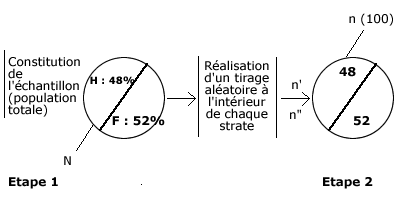
Echantillon par quotas :
- Recréer un échantillon contenant les mêmes proportions dindividus que notre population.
Echantillon de convenance :
- Un prend un échantillon parce que cest le seul que lon puisse trouver.
Echantillon de jugement (à priori) :
- On juge quun échantillon de population correspond au « bon échantillon ».
- Un échantillon aléatoire permet de transposer les résultats (de généraliser) à la population totale
- Principe de linférence statistique.
A. Les méthodes déchantillonnage aléatoires
- Sélection au hasard des répondants où chaque unité de la population mère à la même chance d’être représentée.
1. L’échantillon aléatoire simple
- Ex : tirage du loto, 7 boules sur 49
- Cette technique suppose l’existence d’une liste complète des individus de la population avec leur adresse.
Ex. : liste politique, liste d’abonnés à une même revue...
2. L’échantillon systématique
- On décide de prélever régulièrement des individus de la liste.
- Cette méthode évite qu’on se « promène » à l’aveugle dans une liste.
- N = 1 000 (N = population totale)
- N = 50 (n = échantillon)
Intervalle de sondage
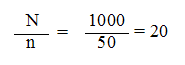
- Donc on fait un tirage régulier tous les 20 individus :
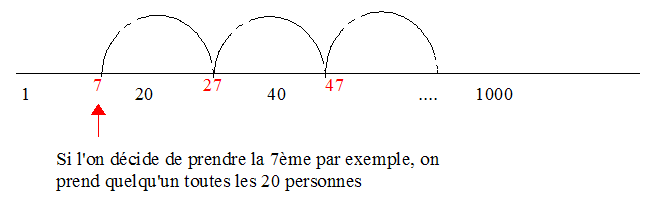
Taux de sondage
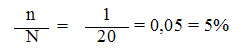
3. L’échantillon stratifié
- Pourquoi recourir à un échantillon stratifié ?
- Parce que la stratification permet de contrôler la constitution de l’échantillon et elle permet d’améliorer la précision des résultats obtenus dans le sondage en éliminant le risque de tirer des échantillons dans lesquels certaines classes seraient largement sur ou sous représentées du fait du tirage au hasard.
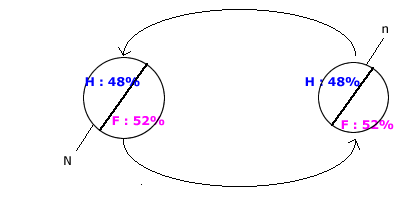
- On effectue dans chacune des states (listes) un tirage aléatoire.
Echantillon stratifié proportionnel
- Echantillon dans lequel la taille des strates est proportionnelle à la taille des strates dans la population.
Echantillon stratifié non proportionnel
- Echantillon dans lequel la taille des strates dans l’échantillon ne respecte plus la proportionnalité de la taille des strates dans la population.
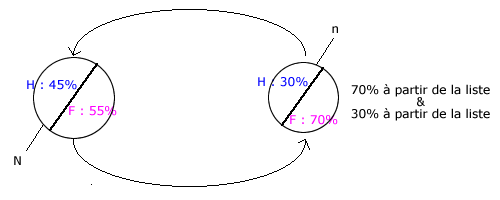
But de la sur représentativité d’une partie de l’échantillon
- Si une partie de l’échantillon est plus homogène et l’autre, l’inverse, on majore cette partie pour minimiser les risques que le hasard se joue de moi.
4. L’échantillon en grappes : (le moins aléatoire des aléatoires)
- On ne dispose pas d’une liste complète mais on veut faire come si on en avait eu une.
- Ex. : Dans une ville on veut interroger des commerçants.
- Problème : on ne dispose pas de la liste des commerçants.
- 1ère étape : décompte de la population (la ville) en grappes (quartiers géographiques) ;
- 2ème étape : sélection aléatoire d’un échantillon de grappes.
- Deux possibilités :
- On interroge tous les commerçants des quartiers,
- Pas le temps de faire ça, alors on décompose nos quartiers en rues.
- Parmi chaque quartier, un tirage aléatoire de rues. Si on constate qu’il n’y a que des rues « riches » on parle « d’effet de grappe », ce qui sous-entend qu’on arrive à la limite de la méthode.
B. Les méthodes d’échantillonnage empiriques
1. L’échantillon de convenance
- Aucune implication du hasard : on décide de tout ce qui vient dans notre échantillon.
- On ne cherche pas à généraliser à la population totale.
- Echantillon guidé par la commodité ou la facilité et non par la représentativité.
- Ex. : Enquête dans les lieux publics, galerie marchande.
- Les membres de l’échantillon se trouvaient à l’endroit et au moment où la collecte d’information a eu lieu.
- Ex. : Enquête par Internet avec mails envoyée et répond qui veut = échantillon de convenance.
2. L’échantillon de jugement (à priori)
- Il existe un souci de représentativité en ce sens que l’on cherche à inclure dans l’échantillon des personnes dont on pense qu’elles détiennent l’information recherchée.
- Interdiction de généraliser ces résultats à la population totale.
3. L’échantillon boule de neige
- Travail sur des petites populations, rares, où il est difficile de repérer les personnes.
Difficulté :
- Trouver au moins une personne (expert),
- Lui soumettre l’enquête et lui demander qu’elle nous mette en relation avec quelqu’un qui fait le même métier.
- Demander aux individus interrogés de construire eux-mêmes leur échantillon.
4. L’échantillon par quotas
- Faire en sorte que l’échantillon reproduise fidèlement les informations statistiques.
- Disposer d’informations statistiques sur la population à étudier (voir suite en face).
- L'échantillon par quotas consiste à disposer à l’avance sur notre population cible ou population de référence.
- Ex. : caractéristiques sociodémographiques.
But : Faire en sorte que l’échantillon reproduise les caractéristiques de la population étudiée.
Pourcentage avec échantillon stratifié :
- On fait des tirages aléatoires (tirés au sort à partir d’une liste) et ce sont donc des personnes précises qui doivent répondre,
- Dans les quotas, il suffit de respecter une proportion (ex. : 60 % H, 40 % F) et on peut prendre n’importe qui dans la rue,
- Attention, en multipliant trop de quotas, il devient difficile de trouver les gens :
- Ex. : Trouver 16 % de femmes de CSP + ayant fait une école de commerce à Nantes (spécialité Marketing)
Limites :
- 1 Choix des variables : Il faut avec un échantillon représentatif LIE AU SUJET et non représentatif des Français par exemple.
- Problème : Trouver des informations sur les sujets.
- 2 Oublie d’un quota important
- Conclusion : Mieux vaut ne pas faire des quotas si on oublie ces deux limites.
Le plan de sondage
- Permet de savoir si la personne interrogée correspond aux attentes du questionnement.
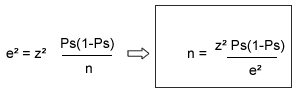
2.1. Détermination de la taille de l’échantillon
- Dépend de deux facteurs opposés :
- L’erreur d’échantillonnage
- Le budget
- Plus on souhaite des résultats précis (avec une faible erreur d’échantillonnage), plus la taille de l’échantillon doit être importante (budget plus élevé).
- Pour déterminer la taille de l'échantillon optimale, il existe trois variables :
- Erreur d’échantillonnage (ou précision)
- Coût de constitution de l’échantillon
- Coûts induits par erreurs d’échantillonnage (conséquences financières liées à une prise de décision qui repose sur des résultats non précis).
- Il n’est pas possible de matérialiser mathématiquement la taille optimale d’un échantillon :
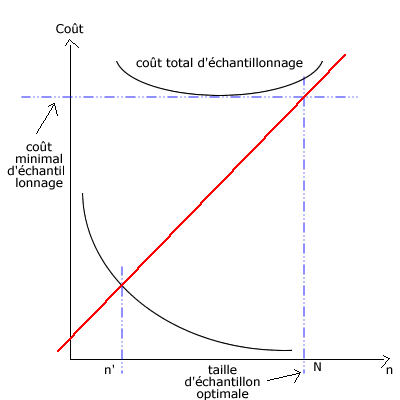
- En travaillant sur des échantillons aléatoires, on peut déterminer mathématiquement la taille de l’échantillon à constituer.
- En travaillant sur un échantillon empirique, c’est le "bon sens" qui parle à notre place
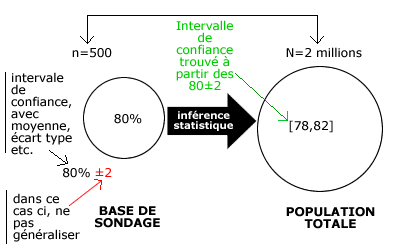
Intervalle de confiance :

- PS : Proportion d’individus possédant une caractéristique au niveau de l’échantillon.
- P : Proportion d’individus possédant une caractéristique au niveau de la population totale.
But : Comment passer de PS à P ?
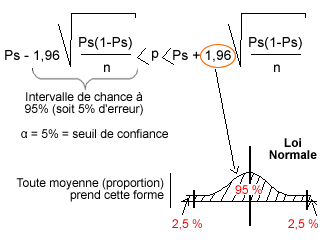
- 2,5 % dans la table de la loi normale nous mène à 1,96. C’est comme ça qu’on arrive à trouver le % d’erreur à 5 % ;
- 1,96 = Zx = valeur lue dans la loi normale (№) au seuil α.
Généralisation
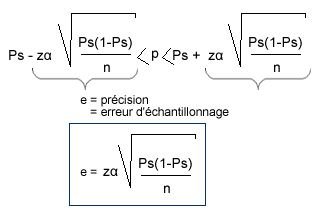
- Attention : Tout ceci n’est valable qu’avec des échantillons aléatoires et non empiriques, car tous les individus ont/avaient la même chance d’être choisis.
- Attention² : Attention, mieux vaut des résultats non significatifs mais avec une méthodologie bien « huilée » que de fournir des résultats « croustillants » basés sur une méthode boiteuse.
top | 2.3. La rédaction du questionnaire
- Problématique complètement ficelée
- Mettre des variables en relation qui existent déjà plus de nouvelles
- Imbrication entre « hypothèse » - « variable » - « problématique » qui donne : le modèle de recherche.
- Variable à expliquer et variables explicatives doivent être regroupées en groupes homogènes sous forme de blocs qui intègrent les sous-variables :
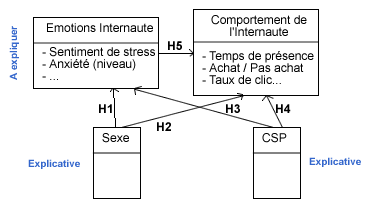
- Les variables explicatives servent à ventiler les variables à expliquer.
- H1 est une hypothèse : le sexe de l’internaute influence les émotions de l’internaute.
- Ensuite, il faut rentrer dans le détail en disant que le sentiment de l’internaute est influencé par le sexe.
- Cette démarche permet de comprendre les relations entre les variables à expliquer.
- Elle permet de résumer les résultats de manière structurée.
- En voyant les croisements des hypothèses, on peut déjà savoir quels tests on va devoir effectuer ;
- D'où l'intérêt de bien connaître les tests possibles.
Attention
- Ne pas subir les tests statistiques et se mettre aux logiciels d’analyse des données au plus tôt.
- Question du questionnaire = tirets
- Voir structure des données = tests
- Variables médiatrices
- Détails des sous-parties
- Variables binaires oui/non
- Binaire/binaire – chi2
- Questions ouvertes – peu dans le questionnaire – avantage = spontanéité
- Pré-codification des questions, etc.
Ex : Pour questions ouvertes/précodage.
Motifs d’insatisfaction du produit X
- Quels sont vos motifs d’insatisfaction ?
- Pas cher
- Pas bon
- Pas sécurisant
- Motifs d’insatisfaction obtenus auprès de 30 personnes
- Quels sont vos motifs d’insatisfaction ?
- Cher
- Pas bon
- Pas séduisant
- Autre
- Réponses à obtenir du questionnaire envoyées à plus que 30 personnes ;
- On conserve l’avantage de la spontanéité de la question ouverte, sauf qu’on a anticipé toues les réponses.
Précodification
- Pré-coder les questions ouvertes, en les pré-testant.
- Ex. : Quels sont vos critères de choix d’une destination touristique ?
- Prix [ ] Spontanéité de la question ouverte
- Destination [ ] Facilité d’utilisation de la question fermée
- Autre [ ]
Les questions fermées
(Voir graphique – Questions fermées)
- La version simple :
- binaire,
- ou dichotomique.
- Ex. : Etes-vous satisfait du produit ? oui [ ] non [ ]
QCM : Réponse unique
- Ex. : Vous mangez du pain :
- le matin,
- le midi,
- le soir
- Un seul choix.
- Ici on force la main des gens.
- Pour les questions sur un individu, il convient d’avoir peu de question sur le comportement, c’est davantage une source d’erreur.
QCM – Réponse multiple
- Le répondant peut retenir plusieurs des résultats proposés.
- Ex. : Parmi les marques de lessive ci-dessous, cochez celles que vous connaissez.
- Ariel oui [ ] non [ ]
- Persil oui [ ] non [ ]
- ce test sprmet de savoir si les hommes ou les femmes connaissent la lessive.
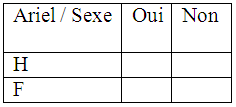
- Pour arriver à obtenir un bon résultat, il faut penser au départ à la codification de façon à ce que le programme traite nos variables facilement.
- La variable dépendante : variable à expliquer
- La variable indépendante : variable explicative
Les échelles d’attitude
- Initialement, elles cherchaient à évaluer les prises de décision/position des individus sur des variables psychologiques.
A. L’échelle de Likert
- C’est un ensemble de propositions évaluatives d’un objet ou d’un concept, positives ou négatives, pour lesquelles le répondant exprime une opinion d’approbation ou de désapprobation, en se référant à une échelle comportant n valeur(s) numérique(s).
- L’échelle de Likert fait apparaître la notion d’accord qui doit apparaître.
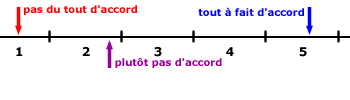
-
Attention ! : si on utilise une fois l’échelle en cinq points, il faut utiliser des échelles en cinq points partout.
-
Idée de constances des échelles à conserver.
-
Une idée de départ quantitative pourra devenir qualitative.
- Intérêt de ces échelles :
- donne lieu à des calculs de moyenne.
- Ex. : Si j’avais une opinion personnelle à émettre sur x, je dirais que c’est un E :
- Soucieuse du respect de l’environnement
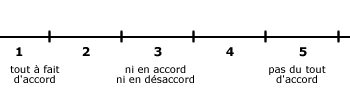
 |
- En utilisant une échelle paire, on force la personne à basculer sur un côté de la balance.
- En utilisant des chiffres positifs, on obtient des moyennes positives, ce qui simplifie les hypothèses.
|
Limite méthodologique – L’effet de HALO
- Biais introduit par la formulation des questions ou par les échelles de réponses traduisant une tendance à répondre de la même façon.
- Ex. : Quand il existe trop de questions, le répondant ne discrimine plus les échelles par des chiffres.
- Pour minimiser l’effet, (quand on a 20 items par exemple) on utilise une échelle pour les dix premières questions.
- Pour les 10 dernières, on modifie le sens des chiffres : on intervertit ce qui empêche les répondants de se lasser.
- Danger : en phase d’analyse statistique, se rappeler de cette interversion.
Idées de traitement de l’échelle de Likert :
- Si on soumet un individu à plusieurs propositions, on peut calculer pour cet individu un score global.
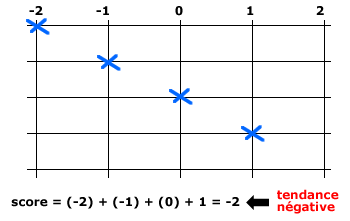
- Si on soumet plusieurs individus à une même proposition, on va calculer le score moyen obtenu par cette proposition.
B. L’échelle sémantique différentielle d’Osgood
- A l’origine, il s’agissait d’échelles constituées de deux adjectifs opposés séparés par n positions intermédiaires.
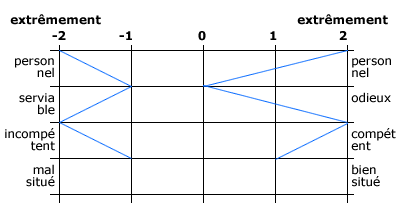
- Présentation des résultats sous forme de serpent (voir graphique d’Osgood).
- Eviter de mettre trop de questionnaires différents dans un seul travail car cela crée des ruptures, et on perd en homogénéité dans le traitement.
C. Echelle à support sémantique
- Ex. : Skip « Micro Plus »

-> ni Likert, ni Osgood, cette échelle est hybride.
|
- Choisir « échelle fermée » pour que le logiciel calcule les moyennes plutôt que les % soient difficiles à traiter.
|
D. Echelle à somme constante
- On demande à un répondant de répartir un nombre de points entre des objets au prorata de l’importance de chaque objet.
- Ex. : répartir 100 points :
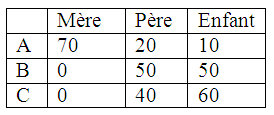
E. Echelle à icônes – smiling faces

- Bien pour les enfants et les illettrées.
Critères de choix d’une échelle :
- Simplicité / Rapidité
- Capacité de transmission de l’information
- Parler de n modalités d’une échelle
- Une échelle en dix points n’est pas forcément meilleure qu’une échelle en quatre points car à partir d’une certaine taille d’échelle, les capacités du répondant sont telles qu’ils ne perçoivent plus de différence.
- Ces répondants nous fournissent alors une pression artificielle.
- Optimum du nombre de points à placer sur une échelle : 7 (+/- 2)
- Traitement de l’incertitude offert aux répondants /
- Oui ou non lui offrir un point neutre ? (échelle impaire ou paire) (Source : Eric Vernette)
2.3.1.3. Les propriétés des échelles de mesure
- Pour l’ordinateur, toutes les variables mesurées se résument à des chiffres.
- Or, derrière les chiffres se trouvent des concepts avec lesquels on ne peut pas faire n’importe quoi.
- Idem avec les chiffres.
Problème :
- Savoir utiliser ces chiffres
- Faire comprendre au logiciel qu’il peut ou ne peut pas faire certaines opérations
- A nous de maîtriser les propriétés mathématiques associées à nos variables.
Tout nombre a trois propriétés :
| L’ordre |
 |
| La distance |
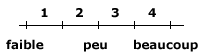
- Il existe le même différentiel sémantique entre faible et peu, et peu et beaucoup
- Les distances entre les nombres sont proportionnelles entre eux.
|
| L'origine |
Les chiffres ont-ils une origine naturelle qui serait le « 0 » ? |
- Dès l’instant que dans un questionnaire nous avons des questions […], selon les propriétés possédées par les questions, on pourra déterminer les tests statistiques qu’il est strictement interdit de faire.
- Il faut maîtriser les chiffres pour savoir quel(s) test(s) faire.
- Il existe trois possibilités par variable donc quatre variables possibles en tout.
- Toute question ne possédant aucune des trois propriétés sera appelée variable nominale ou variable qualitative non métrique.
- Si une variable possède une des trois propriétés on l’appelle : variable ordinale ou variable qualitative non métrique.
- Si une autre variable possède l’ordre et la distance, on parle de variable d’intervalle ou variable quantitative ou variable métrique.
- Si une variable possède « ordre », « distance », « origine », on parle de variable de ratio (de proportion) – variable quantitative ou variable métrique.
- Les variables nominales et ordinales sont qualifiées de variables non métriques (qualitatives).
- Le choix des tests dépend de la nature des variables.
- Les variables d’intervalle ou de proportion sont des variables métriques (quantitatives/scalées).
A. Les variables nominales
- Variable qui permet d’identifier l’appartenance de l’objet étudié à une classe.
- Les nombres vont jouer un rôle très limité permettant d’identifier les objets plus précisément ;
- ces nombres permettent d’établir une relation d’identification ou d’appartenance à une classe.


- On procède à des comptages par classe pour utiliser ces variables.
- Le mode, valeur dominante correspondant au plus grand effectif dans une distribution statistique.
- Ex. : sur 500 personnes, c’est parmi les employés que l’on trouve le plus de répondants.
- Cela permet par exemple de répondre à la question :
- Quelle est la CSP la plus présente dans mon échantillon ?
Test du χ² (chi-deux ou chi2)
- Test à utiliser quand on croise entre elles deux variables nominales.
- Voir la probabilité d’exactitude du tableau.
- Ne jamais interpréter un tableau à l’œil nu.
- Pas de place au hasard.
- Quant un test statistique est > 0, oui à l’interprétation des données car le hasard n’est pas intervenu dans la mise à jour des différences constatées.
- En revanche, un test < 0 veut dire « surtout d’interprétez pas le tableau ».
- Les différences apparentes entre les chiffres sont dues au hasard et non pas au phénomène que l’on cherche à appréhender.
- α = 5 % -> seuil d’erreur tolérable.
- Signifie qu’en interprétant le tableau, on prend 5 % du risque
- χ² = …
- p = 95 %
- 5 % d’erreur et moins : l’idéal en marketing
- Plus il existe d’*, plus le pourcentage d’erreur est bas.
- Si p = 93 % (7 % d’erreur), on utilise les résultats.
- En marketing, tolérance jusqu'à 10 % d’erreur.
- On dira « Nous avons partiellement vérifié nos hypothèses ».
- Attention : Savoir si le logiciel donne la probabilité d’erreur ou la probabilité d’exactitude.
- Il n’existe pas d’uniformité de la présentation de cela.
- Les variables nominales qui prennent deux modalités (sexe) s’appellent variables BINAIRES ou BOOLEENNES.
- Dans une variable nominale, l’ordre n’est pas respecté.
- Idem pour la distance et pour l’origine.
- Aucune des trois propriétés des nombres ne se retrouve dans une variable nominale.
B. Les variables ordinales
- On appelle variables ordinales les variables permettant de classer les objets mesurés suivant une certaine direction ou dimension.
- Les variables ordinales établissent des relations d'ordre.
- La comparaison de ratios n’a pas de sens avec une variable ordinale.
| Ex. : |
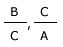 |
- Les comparaisons du type (B – A) ou (C – B) n’ont aucun sens, ne sont pas interprétables.
- Ex. : Trois films préférés à classer de la manière :
1 = +++
2 = ++
3 = +
|
Film A
Film B
Film C |
A > B < C
(film A préféré au film B) |
- L’origine n’est pas respectée car on peut mettre n’importe quoi pour les valeurs de 1, 2 et 3.
- Une variable ordinale ne possède qu’une propriété des nombres : L’ordre
- Avec les variables ordinales, calculs de médiane possible.!
La médiane
- Nombre répartissant les termes d’une série numérique rangés par ordre de grandeur en deux groupes de même fréquence.
- Ex. : Si médiane des notes d’une classe = 7,
- alors 50 % des notes sont < 7, et 50 % des notes sont > 7
Le quartile
- Même raisonnement avec le quartile, 20 % a une note > 7 et 75 % a une note < 7
Le décile
- Même raisonnement avec 10 %, 10 % a une note > 7 et 90 % a une note < 7
Le centile
- Même raisonnement à des 1 % …
Coefficient de corrélation du SPEARMAN (p de Spearman/ro de Spearman)
- Quand on veut croiser deux variables ordinales (coefficient de corrélation).
- Ex. : On demande à deux personnes de classer trois produits A, B, C
1 |
2 |
1 = A |
1 = C |
2 = B |
2 = A |
3 =C |
3= B |
- Attention ! Le coefficient de corrélation appartient à [-1 ; 1]
Coefficient :
- Vers -1 : correlées négativement entre elles
- Vers +1 : correlées positivement entre elles
- Tend vers 0 = non corrélées = indépendantes
- Est-ce que ces deux individus sont très différents ou ont-ils des préférences proches ?
- Tout coefficient de corrélation varie entre :
-1 < p < 1
- Plus le coefficient tend vers-1, plus les profils des individus sont éloignés.
- Il existe une corrélation négative.
- Plus le coefficient tend vers 1, plus les préférences des individus sont identiques, et varient dans le même sens.
- Il n’y a aucun lien entre le classement du premier et du deuxième quand la variable tend vers 0.
- p = - 0,75
Probabilité d’exactitude = 0,9
(PE)
- 10% = probabilité d’erreur
- Corrélation négative assez forte (proche de -1)
- p = - 0,9
- PE = - 90 %
- Belle corrélation mais grand risque d’erreur
- P = - 0,3
- PE = 99 %
- Corrélation assez plate mais pourcentage d’exactitude excellent
- Statistiques retenues
- Ex. : Echelle Lickert
- Relation entre le fait que les chiffres augmentent et par le fait que l’opinion soit de plus en plus positive.
- Toutes les échelles à la base sont ordinales.
- Possibilité de regrouper des ensembles mais ça appauvrit la mesure.
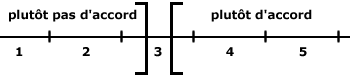
C. Les échelles d’intervalle
- Elles respectent la propriété de l'ordre et de la distance.
- Ex. : 3 villes – Relevés de température
|
A |
B |
C |
Celsius |
0 |
10 |
20 |
Fahrenheit |
32 |
50 |
68 |
- TG = 1,8 Tc + 32
- Ordre : A < B < C
- Distance :
- (C – A) = 20°C
- (B – A) = 10°C
- (C – A) / (B – A) = 2 =
- = 20°C / 10°C = 2
- = 36 F / 18 F
- = 2
- Quelle que soit l’unité de mesure retenue, le rapport des différences est toujours le même.
- Sur une variable d’intervalle, la distance est respectée.
- Origine :
- C/B = 10/10 = 2 différent de 68/50
- L’origine est 0 en Celsius, elle est de 32 ailleurs donc ce n’est pas l’origine universelle.
- Donc on ne peut pas dire quand il fait 20°C qu’il fait deux fois plus chaud que quand il fait 10°C.
- Les calculs de moyennes et d’écarts types vont commencer à prendre du sens.
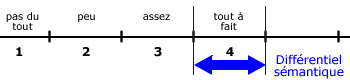
- Hypothèse : Je suppose que mes répondants perçoivent de manière identique les différences sémantiques entre les échelons de l’échelle.
- Cette hypothèse permet de justifier les calculs de moyenne et d’écart type.
- Les scientifiques ne sont pas d’accord avec ce type d’échelle car on ne peut avoir les mêmes perceptions d’échelles.
- Ex. : Goûter un yahourt, dire s’il est sucré ou non
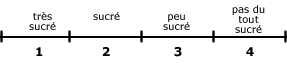
D. Variables de proportion (ou de ratio)
- Voici une variable qui prend en compte les trois propriétés d’un nombre – (ordre, distance, origine).
Ex. :
- Toutes les opérations arythmétriques sont autorisées avec ce type de variable.
- On les collecte à l’état brut.
L’induction
- Quand on veut passer des résultats de l’échantillon aux résultats généraux.
- Exercice avec le questionnaire :
- Influence des émotions sur le comportement des consommateurs.
- Ex. : Croiser la question 2 et le sexe
- Est-ce que le sexe influence le moment où on effectue ses courses ?
- Variable à expliquer : le moment
- Variable explicative : sexe
- Test à appliquer : χ²
|
Semaine |
En fin de semaine |
M |
80 % |
20 % |
F |
60 % |
40 % |
- M – F : Variables explicatives
- Si notre test est vrai, on vérifiera que le moment compte pour affirmer notre hypothèse.
- On pourra déduire :
- Que les hommes font plus leurs courses en semaine que les femmes
- Ex. : Croiser les questions 9 et 15
- 1ères lignes
- Question : Est-ce que les personnes qui consomment le chocolat le midi avec le café ont une incidence sur la qualité ?
- Est-ce que le moment a une influence sur le critère de qualité ?
- Réponse : Coefficient de SPERMAN (p)
- p = 0,45
- p (erreur) satisfaisante
- Plus un consommateur (de chocolat) consomme souvent un chocolat pendant/avec le café le midi, plus le critère de choix "qualité" est considéré comme important lors de l’achat.
- Si p = - 0,45
- Moins je consomme de chocolat à midi avec le café, moins je fais attention à la qualité.
- Variable explicative : moment de consommation,
- Variable à expliquer : le type de critère de choix.
- Hypothèse : L’importance accordée aux critères de choix du produit varie selon son moment d’achat.
- Il existe six moments de consommation :
- - midi, café
- - ...
- - ....
- - TV
- Il existe huit critères de consommation :
- - qualité
- - ...
- - ...
- - consistance
- Pour vérifier l’hypothèse Hn, il faudrait voir 48 traitements statistiques (8 x 6) [ p de SPEARMAN ].
- Si sur 48 p, 40 sont interprétables et 8 non interprétables, il faudrait parler de « confirmation partielle » et le mentionner dans l'article de recherche.
top | 2.3.2. Les règles de forme
2.3.2.1. La rédaction
- Rédiger le questionnaire en fonction du vocabulaire du répondant (rôle du pré-test fondamental).
- Eviter de poser des questions dans lesquelles les modalités peuvent être interprétées de manière subjective. Notamment les adverbes liés à la perception du temps : « souvent », « rarement ».
- Quantifier le plus souvent possible en utilisant des unités métriques.
- Eviter les phrases qui peuvent placer le répondant dans une situation d’infériorité.
- Connaissez-vous ?
- Savez-vous ?
- Avez-vous entendu parler de ?
- Eviter les doubles négations dans les questions.
- Ex. : Ne pensez-vous pas ?
- Une question = une variable = une idée.
- Formuler les questions de manière courte (maximum 20 mots)
- Interdiction de faire évaluer plusieurs choses dans une même question.
- Ex. : Pensez-vous que l’accueil du client et la qualité du service proposé soient satisfaisants ?
- OUI [ ] – NON [ ]
- Le caractère trop directif des questions posées maximise le risque d’apparition de mécanismes psychologiques de défense ;
- phénomène d’autant plus vrai que la personne interrogée se sent impliquée par le questionnaire.
2.3.2.2 La structure du questionnaire
- Présenter le sujet de manière floue
- Dire qu’on est étudiant, qu’on parle d’Internet, des NTIC
- De manière vague, générale.
- Faire en sorte que la première question l’intéresse
- Ex. : « Racontez-moi pourquoi vous n’utilisez pas Internet »
- Questions qualifiantes
- On ne pose pas les mêmes questions aux répondants.
- Plus on utilise des questions filtres, moins le sujet est bien ficelé.
- Attention à trop de questions qualifiantes !
- Questions de mise en route
- Aller sur plus simple au plus compliqué
- Questions spécifiques
- Identification du répondant
- Age :
- difficile à obtenir, ce qui justifie le recours aux classes d'âges
- On ne peut rien faire avec cela.
- Revenu :
- Se demander si cette question porte un intérêt
- Demander le montant net par mois (plus compris)
- Préciser si on parle du revenu du ménage ou du répondant
- Le revenu du ménage passe mieux
2.3.2.3. Présentation du questionnaire
- Structurer le questionnaire de façon lisible et clair.
- Quand on soumet une échelle en sept points, tendre un support cartonné pour éviter que le répondant ne voit la fin du questionnaire avant l’heure.
2.3.2.4. La codification du questionnaire

- Mettre DATE et LIEU d’ADMINISTRATION sur le questionnaire
- PRE-TEST : Environ vingt personnes sélectionnées comme l’échantillon de notre enquête (de manière aléatoire).
- Attention ! Le questionnaire peut se présenter comme une dissertation présentant les questions en parallèle aux variables.
Les variables nominales
- Les plus pauvres sur le plan statistique.
- Ne possèdent ni ordre, ni distance, ni origine.
- Avec ce type de variable, le nombre collecté sert uniquement à identifier l’individu.
- = ouvrier [ ]
- = employé [ ]
- = …
- 8 = inactif [ ]
Ordre :
- Ne s’applique pas. L’ordre associé aux chiffres ne correspond pas au concept mesuré.
Distance :
- Ne s’applique pas.
- La distance indique qu’il n’existe pas de proportions entre deux concepts.
Origine :
- Ne s’applique pas.
- L’origine montre qu’on se moque des chiffres (on peut parler de 10 à 80 au lieu de 1 à 8) donc de l’origine.
- Les variables nominales montrent l’appartenance à une classe.
- Elles s’appliquent aux questions fermées essentiellement.
Types de traitements
Comptage :
- Sur une population, il existe x % d’employés.
- Attention ! Il est impossible d’effectuer des moyennes de ce type de valeur.
- L’ordinateur ne sait pas que nous parlons de valeur nominale et ne doit pas effectuer cette moyenne.
Tableau de contingence
- Tableau qui croise 2 variables nominales entre elles.
- Le test du χ² permet de savoir si on peut croiser des variables nominales entre elles (association de deux valeurs nominales).
- Ex. : Etes-vous satisfait du X ?
- = OUI
- = NON
Sexe :
- = H
- = F
- Allure du tableau qui apparaît ans ce style :
- Attention ! Impossible de comparer des % à l’œil nu d’où l’importance de lancer le test du χ²
- Si le χ² montre que l’on peut interpréter les %, c’est que les différences sont significatives (entre les deux %), et donc nous pouvons interpréter.
Les variables ordinales
- Ex. : Citez-moi vos trois films préférés (par ordre d’importance décroissante)
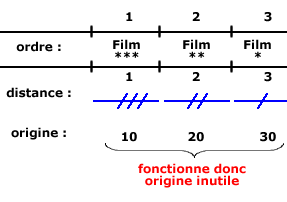
- Ordre : respecté
-
Distance : non respectée
- Origine : non respectée
- A la base, toute échelle d’attitude (Likert, Osgood, Sémantique) est assimilée à une variable ordinale.
- Le p (ro) de Spearman est donc un indicateur qui sera fortement utilisé
- On va supposer que l’ensemble des répondants de l’échantillon perçoit comme identique les distances entre les échelons de l’échelle et les distances associées à chaque support sémantique de l’échelle.
- C’est la condition nécessaire pour pouvoir faire des moyennes.
Le masque de saisie
- on choisit entre les variables (nominales, ordinales, d’intervalles, de ratio) dans le logiciel de statistiques.
Les variables de proportion
- Les plus riches.
- Elles possèdent les trois propriétés (ordre, distance, origine).
- Les quatre catégories de variables doivent être considérées comme reliées entre elles par une relation hiérarchique allant de la plus pauvre à la plus riche.
- Chaque variable possède toutes les propriétés statistiques de l’échelle qui lui est inférieure plus d’autres propriétés qui lui sont spécifiques.
- Ex. : Une échelle de proportion possède les propriétés des échelles ordinales, nominales, d’intervalles.
L’échelle de Lickert
- Risque d’utiliser les échelles de Lickert négatives
- Des notes négatives –> des moyennes négatives difficiles à traiter ; et rendant difficile la création des hypothèses
- Exemples de traitements (voir graphique BANK)
- Calcul d’un score moyen par ite
- 300 répondants – classement du score moyen grâce aux moyennes.
- Ceci permet de hiérarchiser les idées.
- Logique confirmatoire plutôt que de tendance
- Pour chaque répondant, calcul d’un score global de satisfaction, en additionnant les quatre notes (partant du principe que l’échelle va de 1 à 5, le score mini est de 4 x 1 = 4 et le score maxi est de 4 x 5 = 20).
- Echelle de Lickert = échelle additive d’où la possibilité de faire des sommes.
B. L’échelle sémantique différentielle d’Osgood
- Raisonnement par item : score moyen (moyenne)
- Raisonnement par individu : score additif (Somme)
- Le score additif peut être négatif, pas le score moyen.
C. L’échelle à support sémantique
- Utilisation du mot « IMPORTANT »
- Ex1. : Quelle importance accordez-vous … ?
- Echelle avec le mot important
- Ex.2 : Quelle utilisation faites-vous … ?
- Echelle avec « j’utilise » / « je n’utilise pas », etc.
Problématique générale des tests statistiques
1. Objectif d’un test
- Un test est une procédure d’analyse, de calcul, dont le but est de donner les moyens à l’analyste de décider objectivement si un résultat donné est révélateur d’une certaine réalité ou au contraire attribuable à divers impondérables survenant lors de la constitution de l’échantillon.
Concrètement :
- Nous sortirons des tableaux chiffrés
- Que nous n’interpréterons pas à l’œil nu,
- Et dont nous saurons grâce au test, si nous pouvons les interpréter ou non, selon les erreurs impondérables ou erreurs d’échantillonnage.
- Plus les erreurs d’échantillonnage sont fortes, plus les interprétations sont mauvaises.
2. Procédure de mise en œuvre d’un test
2.1. Procédure de type hypothético-déductive (Epistémologie)
- Lecture – digestion – hypothèse – test des hypothèses
- La formulation des hypothèses
- Deux hypothèses :
- H0 : hypothèse nulle
- H1 : hypothèse alternative
- En règle générale, H0 est l’hypothèse que l’on souhaite rejeter au profit de H1.
- Comme on est dans le cadre de l’inférence statistique (qui consiste à passer des résultats de l’échantillon à la population totale), les hypothèses seront toujours en référence à la population totale.
- D’où l’intérêt d’avoir des échantillons représentatifs lors des tests.
2.2. Le choix du test
- Le test permet de mesurer la manière dont les valeurs de l’échantillon se comportent par rapport à l’hypothèse nulle.
- Le choix du test ne dépend pas de la nature des variables :
- Nominale - …
- Intervalle -…
2.3. Décision
- Le test va calculer, pour un certain niveau d’erreur fixé une zone de rejet ou une zone d’acceptation autour de l’hypothèse nulle.
- Si la valeur calculée pour le test se situe dans la zone de non rejet, alors on retiendra H0.
- Si la valeur du test se trouve dans la zone de rejet H0, alors on retiendra H1 :
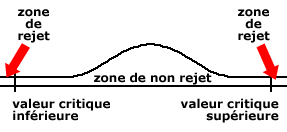
Cas de H0 :
- Les différences constatées dans le tableau à l’œil nu sont dues au hasard, aux erreurs d’échantillonnage.
- Donc, pas d’interprétation du tableau,
- = le test n’est pas bon.
Cas de H1 :
- Les différences constatées entre les valeurs du tableau sont trop importantes pour être dues aux erreurs d’échantillonnage ou au hasard.
3. Le test du χ²
3.1. Objectifs du X2
- Ce test s’applique à des données nominales.
- Dans le cadre d’un croisement de deux variables entre elles, le χ² vérifiera l’existence d’un lien d’association entre les variables.
3.2. Hypothèse formulées par le logiciel
- H0 : Dans le cas d’un test de χ², cette hypothèse postule qu’il n’existe pas de différences entre les valeurs du tableau.

3.3. Règles de décision
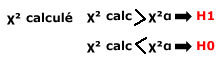
4. L’analyse de la variance
4.1. Objectifs du test
- Variables explicatives = nominales
- Variables à expliquer = métriques (intervalles, proportions).
4.2. Applications
- Variables explicatives : SEXE
- Variables à expliquer : VITESSE
Vitesse |
Sans |
Peu |
Assez |
Très |
Masculin |
63% |
5,4% |
4,05% |
27,03% |
Féminin |
1% |
23,6% |
16,88% |
58,4% |
- χ² = 77,14%
- 1-p = 99%
- Test de moyenne = cas particulier de l’analyse de la variable
- F = calc = 62,77
- p = 99,99 %, cela signifie qu’on a 0,01 % de chance de se tromper en confirmant H1.
- Possibilité d’effectuer un tableau avec plusieurs critères.
- Les échelles de moyenne sont plus faciles à interpréter que des tableaux de χ².
5. Coefficient de corrélation
- Il existe une diversité très forte de corrélation comme nous l’avons vu.
- Le coefficient de corrélation varie toujours entre -1 et 1 ;
Le R de Pearson (le croisement entre deux variables métriques)
- Approfondir : corrélations multiples
- Variables à expliquer : « confort »
- Variables explicatives : « âge »
- Explication : Plus on vieillit, plus on a besoin de confort.
- Faille du système : Il manque la probabilité d’exactitude (présent dans SPSS)
- SPHINX : Logiciel terrain qui ne convient pas (en dehors de la variance du X2) à la Recherche et à l’exigence qu’elle comporte. Mieux vaut alors utiliser SPAD et SPSS ;
Attention ! La probabilité d’erreur est une donnée nécessaire à l’interprétation des résultats.